Say we work for a medium to large organization. Consider a typical scenario where we need to find a particular record produced a few days ago or a subset of records matching specific criteria.
This article will explore different approaches to read the Apache Kafka topic's messages.
Apache Kafka is a real-time streaming datastore used by over 80% of all Fortune 100 companies.
Instead of tables, you have topics, which are the main building blocks to store the records and events. They benefit from high throughput, transparent replication, and sharding also called partitioning.
Apache Kafka can scale from one small machine to a massive cluster of hundreds of virtual machines.
This section will cover what tools are available to consume a topic using a terminal.
We will start with the official command-line tools provided by Apache Kafka. These come with every Kafka installation, and if you are running a local Kafka, you may already have them.
After that, we will cover a popular third-party tool called kafkacat, with over 3000 stars on GitHub, and mention a few others that may be useful as an alternative.
The Apache Kafka installation contains useful command-line tools to interact with Kafka and Zookeeper via the command line.
Once extracted, you can find the executable kafka-console-consumer under the bin directory.
Let's imagine, we want to read all the values in the topic character.json.schemaless. The following instruction would do the job:
./bin/kafka-console-consumer \
--bootstrap-server localhost:9092 \
--topic character.json.schemaless \
--group my-group-id \
--key-deserializer org.apache.kafka.common.serialization.StringDeserializer \
--value-deserializer org.apache.kafka.common.serialization.StringDeserializer \
--from-beginning
If we rerun the same instruction, we won't get any results even if you pass the flag --from-beginning. Believe it or not, this is the expected behaviour. Apache Kafka brokers keep track of the last committed offset consumed by any consumer group so that the next time they consume, they will resume from there.You can find the complete list of flags that you can use with kafka-console-consumer:
# ./bin/kafka-console-consumer flags
--bootstrap-server # <String: server to connect to>
--consumer-property # <String: consumer_prop>
--consumer.config # <String: config file>
--enable-systest-events
--formatter # <String: class>
--from-beginning
--group # <String: consumer group id>
--help
--isolation-level # <String>
--key-deserializer # <String: deserializer for key>
--max-messages # <Integer: num_messages>
--offset # <String: consume offset>
--partition # <Integer: partition>
--property # <String: prop>
--skip-message-on-error
--timeout-ms # <Integer: timeout_ms>
--topic # <String: topic>
--value-deserializer # <String: deserializer for values>
--version
--whitelist # <String: whitelist>
While the official Kafka tool can do the job in most use cases, some users might find scenarios where they want more control over the headers or offsets.
That's when kafkacat may be more useful.
Similar to kafka-console-consumer, the consumption of all the messages in a topic with kafkacat is quite simple:
kafkacat -b localhost:9092 -t character.json.schemaless -G my-group-id
We'll usually need more control over what offsets we use to the read topic in real-life scenarios. For instance, we might need to consume the last 200 messages. We can do so by running:
kafkacat -b localhost:9092 -t character.json.schemaless -G my-group-id -o -200
Aside from kafka-console-consumer and kafkacat, there are other tools with similar functionality. When writing this article, we found:
kafka-console-consumer written in Python.When the Kafka cluster gets larger and the use cases more complicated, intuitively visualizing topics becomes harder.
Standalone clients can navigate and understand what information is available in your cluster and present it nicely so you can explore and manage what's in it easily.
Some of these focus more on Kafka's sysadmin and DevOps operations, providing advanced cluster management features. CMAK (previously Kafka Manager) is probably the most used.
Other tools focus on the visualization and consumption side, providing advanced visualization features over the topics, messages, and configurations. Kafka Tool, kafdrop, and Kafka IDE, are the most widely used.
We will dive and introduce some of these tools. Since this article is about consuming Kafka topics, we will focus on the latter category.
GUI desktop application that allows you to visualize topics and messages. One of the key benefits is that you don't need to deploy a custom service in your infrastructure.
Kafka Tool licenses start at 79$ per user for teams of up to 10 developers, dropping for larger groups. You can read more about its features here.
Open-source web service that provides a web UI where you can browse topics and messages.
Compared to Kafka Tool, it's free with very similar functionality. You may need to host it in your infrastructure for shared access or directly run it on your machine.
A desktop application that provides advanced features on observability and data visualization with fundamental administration options.
Compared to the other two solutions, Kafka IDE goes one step further by analyzing and inferring your values and keys' schema. This way, you can build queries and visualizations based on the nested values within a message.
To do so, Kafka IDE blends your Schema Registry (Avro, Protobuf, and JsonSchemas) with a smart inference mechanism that uses message samples from the topic.
If your team doesn't use Schema Registry or that specific topic doesn't have a registered schema, don't worry because the smart inference is just enough. In the image below, you can see an example of a topic containing JSON messages without registered schemas. Note how it can even find embedded fields within raw string values.
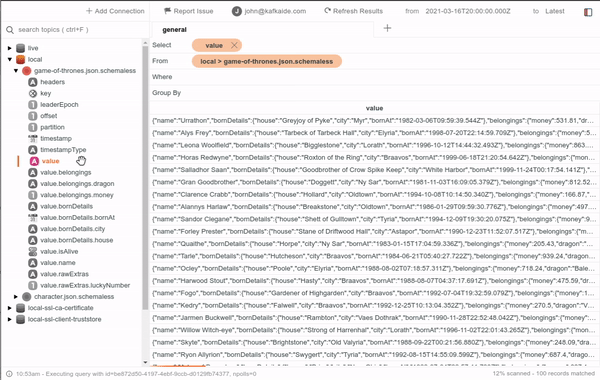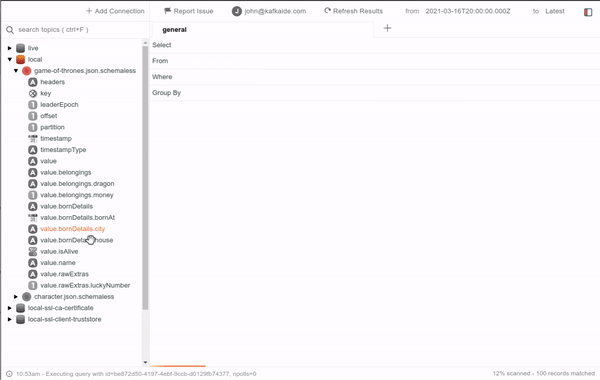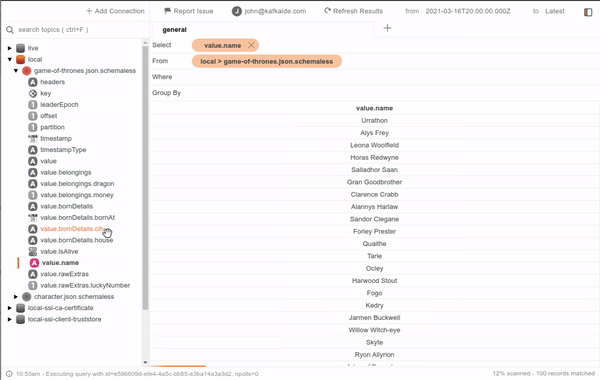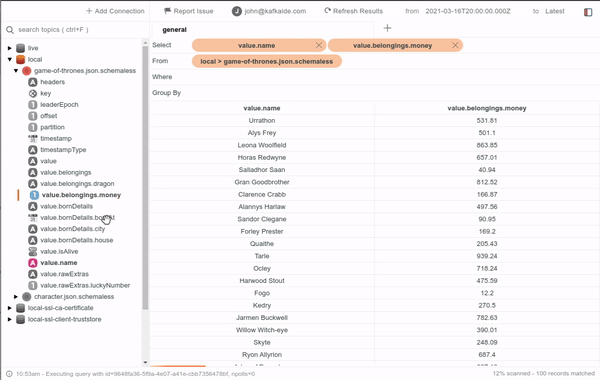
By now, Kafka IDE also provides message filtering. It has quite a robust operation set similar to those offered by other tools like Tableau. Some of these operations let you filter based on date or number ranges, regular expression matching, boolean masking, null handling, and more.
When writing this article, the Kafka IDE license is free while in Open Beta Stage.
The third and last approach we will explore is consuming Kafka topics using existing code libraries.
This approach has many benefits, but the most important one is that you are good to go as long as you can express your needs using code.
The Apache Kafka's client libraries are written in Java, so any language that runs on the Java Virtual Machine (JVM), mainly Java, Kotlin, and Scala, can use that library directly in their codebase.
For anyone that is not aware of how JVM works, any application written in any language that runs on the JVM will ultimately share the same binary code (in reality, this high-level binary code is called bytecode since a virtual machine then interprets it).
This is important because this allows you to mix multiple languages since they will ultimately be compiled to the same bytecode, avoiding the overhead of serialization - deserialization of data.
Here is an example where we consume a topic using KafkaConsumer API in Java, apply a specific function to filter the messages based on custom conditions, and then do something with those messages. CTA
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("group.id", "consumer-group-id-1");
properties.put("auto.offset.reset", "earliest");
properties.put("key.deserializer", StringDeserializer.class.getName());
properties.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Pattern.compile("character.json.schemaless"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5));
for (ConsumerRecord<String, String> record : records) {
if (matchesCondition(record)) {
doSomething(record);
}
}
}
consumer.close();
Any other language that doesn't run on the JVM must use the Apache Kafka's Protocol API. This approach consists of serializing the data you want to transfer using the Apache Kafka's Protocol standard so that both ends can deserialize in their respective language. You can find a table on how the different data types translate here if you want to write your own Apache Kafka client library.
Lucky for us, there are well-maintained client libraries out there that abstract the details of this protocol so we can directly use the high-level API similar to the JVM one.
Most of these implementations rely on the C language implementation of the Apache Kafka protocol named librdkafka, which provides Producer, Consumer, and Admin clients.
You can find here some of the available client libraries.
We will illustrate this approach by showing an example of consuming messages in Python using the
We'll use Python and the confluent-kafka-python library for our full example down below to solidify how these libraries compare to the Java one.
consumer = Consumer({
'bootstrap.servers': '127.0.0.1:9092',
'group.id': 'consumer-group-id-1',
'auto.offset.reset': 'earliest'
})
consumer.subscribe(['character.json.schemaless'])
while True:
record = consumer.poll(5.0)
if record is None:
continue
if record.error():
print("Consumer error: {}".format(record.error()))
continue
if matchesCondition(record):
doSomething(record)
consumer.close()
As we can see, it is very similar.
This approach's main caveat is that the KafkaStreams API is still not widely supported for non-Java languages. For example, librdkafka maintainers made it clear that there are no plans of supporting this API anytime soon - see GitHub issue.
Kafka REST Proxy can be a good alternative if using client libraries is difficult.
The Rest Proxy service works by providing a RESTful interface to an Apache Kafka cluster. Now, any client with access to that API Rest can consume messages from the Kafka cluster. This has the advantage that it is possible to use this approach from any language or platform where HTTP requests are supported.
The caveat with this approach is that you need to keep instances of this proxy running on machines with access to the Apache Kafka cluster. You may also need to monitor for load usage since this could become your infrastructure's bottleneck between the cluster and your clients.
Let's see some generic examples of this approach.
# step 1: create consumer
curl -X POST \
-H "Content-Type: application/vnd.kafka.v2+json" \
--data '{"name": '"$CONSUMER_ID"', "format": "json", "auto.offset.reset": "earliest"}' \
http://127.0.0.1:8082/consumers/$CONSUMER_GROUP_ID
# response:
# {
# "instance_id":"$CONSUMER_ID",
# "base_uri":"http://localhost:8082/consumers/$CONSUMER_GROUP_ID/instances/$CONSUMER_ID"
# }
# step 2: subscribe
curl -X POST \
-H "Content-Type: application/vnd.kafka.v2+json" \
--data '{"topics":["character.json.schemaless"]}' \
http://localhost:8082/consumers/$CONSUMER_GROUP_ID/instances/$CONSUMER_ID/subscription
# step 3: consume
curl -X GET \
-H "Accept: application/vnd.kafka.json.v2+json" \
http://localhost:8082/consumers/$CONSUMER_GROUP_ID/instances/$CONSUMER_ID/records
# step 4: close consumer
curl -X DELETE \
-H "Content-Type: application/vnd.kafka.v2+json" \
http://localhost:8082/consumers/$CONSUMER_GROUP_ID/instances/$CONSUMER_ID
In this article, we introduced Apache Kafka and its general traits. We also presented a typical scenario that often happens when we work with this technology.
We started by talking about consuming messages from topics by using the terminal. To do so, we used the Apache Kafka command-line tools and kafkacat.
We also covered standalone tools that facilitate the job, highlighting Kafka IDE for its robust field schema inference and message filtering based on custom constraints.
Finally, we focused on and covered the basics of the different programmatic approaches we can have depending on our language of choice and environment. We covered the official library for JVM languages and other well-maintained libraries based on the Protocol API for non-Java compatible languages. Lastly, we talked about the Confluent REST API for situations where communication via HTTP requests is preferred.
If you liked this article, don't forget to follow us on Twitter. to get notified when we publish new articles.
