The recent rise of distributed systems has pushed Apache Kafka as one of the most sought-after technologies and is currently used by most of the big companies worldwide.
Apache Kafka is a distributed streaming platform and is useful for building real-time streaming data pipelines to get data between different systems or applications.
In this post, you're going to learn how to leverage Kafka as a Python programmer, so you too can start building distributed systems using this powerful technology.
The first thing we need to do is to set up Kafka locally and run a little "hello world"-type test to check that everything is working as expected (in the Kafka world this means to use the terminal to send and read some messages), then we'll jump to the fun python part where we will write some code to interact with Kafka, specifically a Kafka producer and consumer.

Kafka is available in two different flavors: one offered by the Apache software foundation and the other by Confluent Kafka.
If you're new to Kafka chances are that you don't know who these confluent people are, Confluent is an American big data company founded by three LinkedIn Engineers, who were part of the original team behind the creation of Kafka.
Confluent Kafka is mainly a hosting solution for Apache Kafka. It provides most of the Kafka features plus a few other things.
For the rest of this tutorial, we'll be using the Apache Foundation version of Kafka just to keep things simple.
To get Apache Kafka up and running on your computer, you'll need to follow these steps:
1. The first requirement is that your local environment must have Java 8+ installed.
sudo apt update
sudo apt install default-jdk
2. The next step is to download it.
tar -xzf kafka_2.13-3.1.0.tgz
cd kafka_2.13-3.1.0
3. Running the following command will start all the needed services in the correct order, keep it running in the background.
bin/zookeeper-server-start.sh config/zookeeper.properties
4. Finally, on another terminal session run:
bin/kafka-server-start.sh config/server.properties
Once all services have successfully started, you will have a basic Kafka environment running locally and ready to use. But before we continue, there are some concepts that need to be understood.
Did you notice that we needed 2 different commands to start the Kafka environment? One of them made use of Zookeeper. You may be wondering what it is and why do we require it.
To put it simply, Zookeeper is a top-level software also maintained by Apache that acts as a centralized service used to maintain naming and configuration data. It provides a robust synchronization within distributed systems. Zookeeper keeps track of the status of the Kafka cluster nodes, Kafka topics, partitions, etc.
In the future (soon) ZooKeeper will no longer be required by Apache Kafka, but in the meantime, we'll have to deal with it.

A message, also called a record or event, is the basic piece of data flowing through Kafka. These messages are how data is represented inside Kafka. A message is made out of 4 parts.
- An optional Key.
- A value (where the content of your data goes).
- A timestamp.
- Some optional metadata headers.
Other examples of possible messages might be payment transactions, geolocation updates from mobile phones, shipping orders, sensor measurements from IoT devices or medical equipment, etc.
After the message, the second main concept in Kafka is the broker, they can be thought of as the server-side of Kafka. A Kafka cluster is formed by one or more Kafka brokers.
Following this short explanation, we are going to create a topic and send a message to it from the command line first, and then we will do the same thing using a python script.
One thing to note is that Kafka was built with the command-line in mind. There is no official GUI, the closest thing that may aid us are projects like KafkaIDE.
All messages are stored in a topic. And in turn, topics consist of units called partitions. To say it another way, one or many partitions make up a single topic.
While the topic is used to logically organize messages in Kafka, a partition is the smallest storage unit that holds a subset of records owned by a topic.
To create a new topic, you can run the following command (we will use this topic later in our python demonstration):
bin/kafka-topics.sh --create --topic employees --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092
If we don't specify the number of partitions when creating a new topic, it will use the broker's default configuration, by default only 1 partition per topic.
Kafka acts as a centerpiece in the communication between different services. Some of them produce messages, others consume messages, these are the Kafka producer and consumer.
A Kafka producer is a client application that publishes (writes) messages in a Kafka topic, and a Kafka consumer subscribes to that same topic to read and process those messages.
A Kafka client communicates with the Kafka brokers via the network for writing and reading messages. Once received, the brokers will store the events in a durable and fault-tolerant manner for as long as you need them.
Unlike Amazon Kinesis and Google PubSub where a message can be stored for a maximum of 7 days, Apache Kafa can act as a database and store the messages forever.
You may run the following console command to write a few events into your topic (it's a basic Kafka producer client). By default, each line you enter will result in a separate event being written on a topic.
bin/kafka-console-producer.sh --topic employees --bootstrap-server localhost:9092
On the consumer side, the easiest way to read out the data from Kafka is to use the terminal as well.
Open another terminal session and run the following console consumer command to read the events you just created:
bin/kafka-console-consumer.sh --topic employees --from-beginning --bootstrap-server localhost:9092
It's important to remark that events within Kafka are durably stored, as I mentioned earlier, and that they can be read as many times and by many consumers at the same time.
If you're able to read some data using the previous command, it means that everything has been set up correctly on your end and that you're ready to use Python to build your own producer and consumer.

To start working with Kafka in Python, we will need a good library that will aid us in the process.
Luckily there are multiple libraries available for us to choose from, the most important ones are:
For this tutorial, we'll go with the popular option, the kafka-python library. In the words of their creators, it is designed to function much like the official java client, with a sprinkling of pythonic interfaces
To start working with it, you can open up a terminal and install it using pip:
pip install kafka-python
This is the part where we will be doing some actual python coding to create a producer.
What we will do now is to create a python script to produce some messages that will be sent to the "employees" Kafka topic that we previously created.
The following code shows you how to connect to the Kafka cluster (our broker) and how to send it different messages. In this example, we have a list of different employees, and we pass their information to the topic one by one.
import json
from kafka import KafkaProducer
def publish_message(kafka_producer, topic_name, key, value):
try:
key_bytes = bytes(key, encoding='utf-8')
value_bytes = bytes(value, encoding='utf-8')
kafka_producer.send(topic_name, key=key_bytes, value=value_bytes)
kafka_producer.flush()
print('Message published successfully.')
except Exception as ex:
print(str(ex))
if __name__ == '__main__':
kafka_producer = KafkaProducer(bootstrap_servers=['localhost:9092'], api_version=(0, 10))
employees = [
{
"name": "John Smith",
"id": 1
}, {
"name": "Susan Doe",
"id": 2
}, {
"name": "Karen Rock",
"id": 3
},
]
for employee in employees:
publish_message(
kafka_producer=kafka_producer,
topic_name='employees',
key=employee['id'],
value=json.dumps(employee)
)
if kafka_producer is not None:
kafka_producer.close()
The interface to communicate with Kafka in python using this library is pretty simple, we instantiate a new KafkaProducer and use its send method to stream some data to the broker.
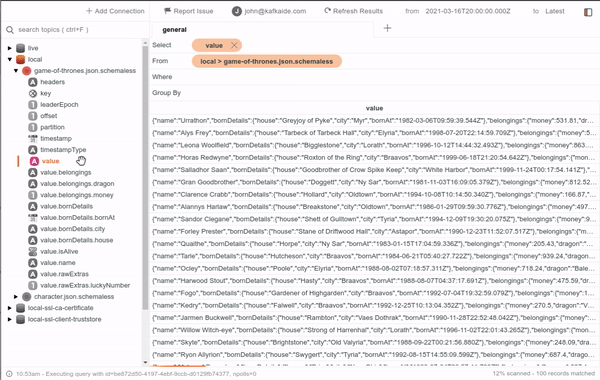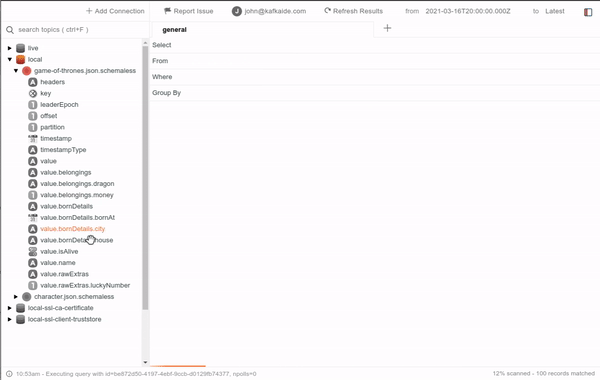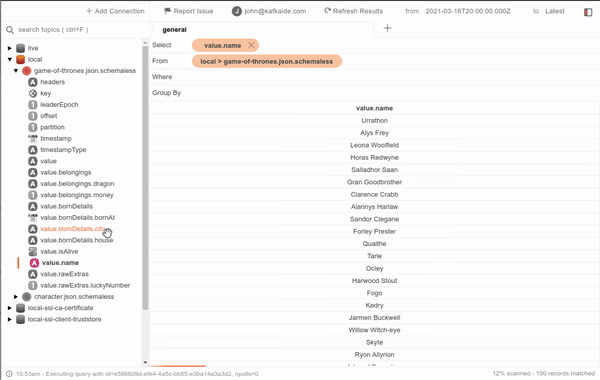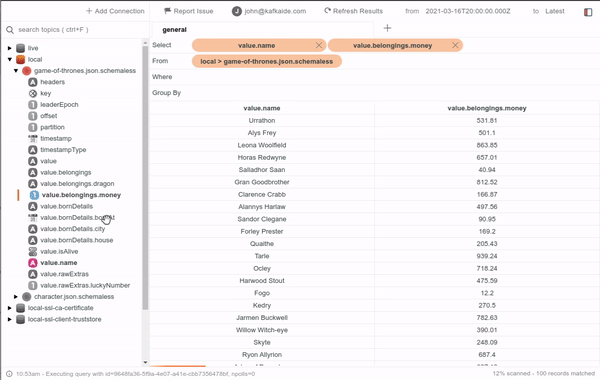
KafkaIDE is a very useful tool when it comes to getting visual help on what's going on in the brokers. You can use it to help you implement and debug your Kafka applications.
It is a desktop application that can run pretty much everywhere and can connect to any cluster wherever is located as long as you have connectivity from your laptop or system, so make sure to check it out!
Now that we have some data on our topic, it's time to set up a python Kafka consumer using the kafka-python library.
The following piece of python code connects to the topic and reads all the messages. It's also important to note that a consumer is not only used to get some data, but to do something with it. In this example, we are just printing out some strings to the console, but you can imagine we can do pretty much anything here.
import json
from time import sleep
from kafka import KafkaConsumer
if __name__ == '__main__':
consumer = KafkaConsumer(
'employees',
auto_offset_reset='earliest',
bootstrap_servers=['localhost:9092'],
api_version=(0, 10),
consumer_timeout_ms=1000
)
for msg in consumer:
record = json.loads(msg.value)
employee_id = int(record['id'])
name = record['name']
if employee_id != 3:
print(f"This employee is not Karen. It's actually {name}")
sleep(3)
if consumer is not None:
consumer.close()
And with these two python programs, the producer and the consumer, now you actually know how to use the combined power of Kafka + Python.
Why would a software developer be interested in learning about Apache Kafka?
Kafka is an awesome, scalable, fault-tolerant, stream processing, publish-subscribe messaging system that enables you to build distributed applications.
This technology is quickly becoming the bread and butter of many companies. It's a tool that's in great demand because it provides a lot of value to organizations, and we as programmers must always keep up to date with trends like this one.
In this post, we covered the gist of Kafka and how to interact with it using python. To learn more about these topics, feel free to explore more articles from this blog ;)
