The setup to create and scale an Apache Kafka cluster can be a pain to deal with, that's why AWS came up with the MSK service back in 2019. AWS MSK is a fully managed cloud service for Apache Kafka so that developers don't have to worry about the underlying infrastructure. It's a good solution if you want to use Apache Kafka without the overhead.
In this post, I want to give you a quick overview of what this service is about, how to start using it, and compare it with some of the alternatives so you can make the right decision about which one to use.

The MSK service stands for Managed Streaming for Apache Kafka. It's the service that Amazon offers so that you don't have to self-manage your Apache Kafka clusters, and spend a lot of time securing, scaling, patching, and ensuring that the Apache Kafka clusters are available, the same for Apache ZooKeeper, which Apache Kafka depends on for resource management.
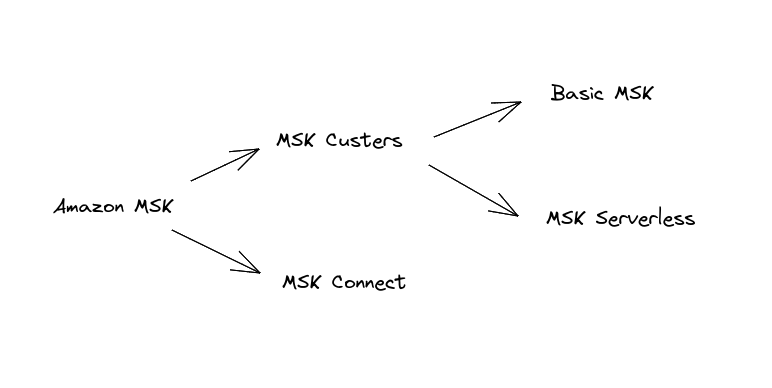
As Apache Kafka is getting more popular, this service is also getting more attention, and now it offers us 3 main tools.
- Basic MSK
- MSK Serverless
- MSK Connect
I'll cover each of these next.
Some of the key features of Amazon MSK:
When you first enter the Amazon MSK console, you will find 2 main menu sections, MSK Clusters, and MSK Connect.
Clusters. You can get started here. When creating a new cluster we have 2 main options, "Quick create" and "Custom create". The first option comes with lots of defaults following best practices, the second enables you more customization.
After that, the second decision we need to make is whether we want to provision some servers for the brokers or if we want to go serverless and let amazon handle this for us.
When you create a new cluster, it will exist within a special Amazon MSK VPC, but you can select the AZs it will be deployed in, so it's located near your servers (ensuring high connection speeds).
Cluster configuration. When you create a new cluster it comes with a default configuration following best practices, but if you want to change that you can do it in this section.
Some of these properties affect a broker and others relate to the ZooKeeper cluster. You can find the complete list of properties here.
This feature makes it easy for you to deploy connectors that move data between Apache Kafka clusters and external systems such as databases, file systems, and search indices.
MSK Connect is fully compatible with Kafka Connect, so you can run your applications with no changes.
Once you have your cluster set up you may wonder, how can you connect to it from your local machine. You have a couple of options here:
NOTE: You can easily test the connection using a free program like KafkaIDE.
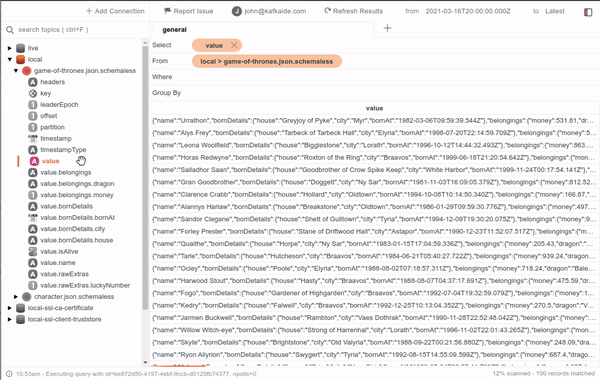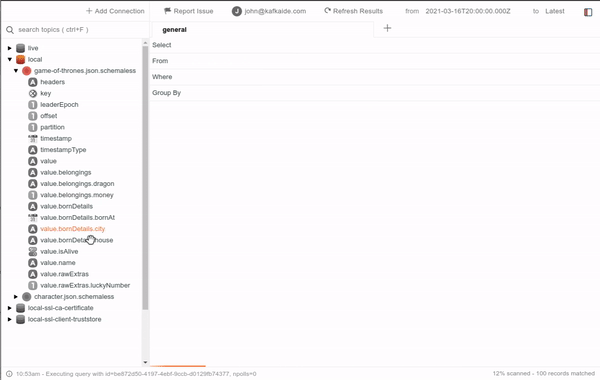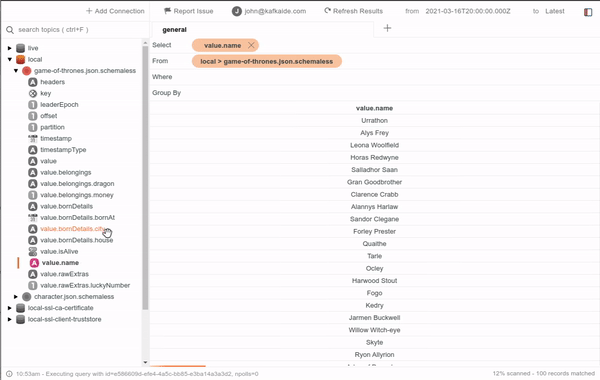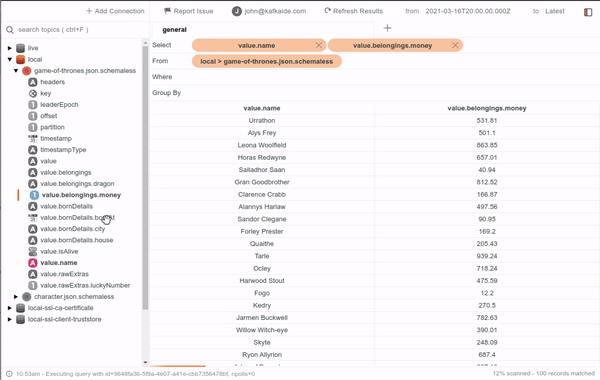
When you create an Apache Kafka cluster with MSK, it’s deployed into a managed VPC with brokers in private subnets (one per Availability Zone as you specify when creating a new cluster). Amazon MSK also creates the Apache ZooKeeper nodes in the same private subnets.
The brokers in the cluster are made accessible to your VPC through elastic network interfaces (ENIs) that will appear on your account.
When using AWS MSK you can run into some problems:
MSK Serverless solves these problems. As I mentioned earlier you can select the serverless option when creating a new cluster.
We have been talking about MSK, another popular amazon managed streaming platform is Amazon Kinesis. These two options are very similar, if you want to dig deeper into their differences you can find a fantastic comparison here by Noel Anson.
Of course, there are some fully managed services outside AWS, one of them is Confluent Cloud. Some considerations when considering if Confluent Cloud may work better for you:
You can find a good overview of the platform here.
Now we are near the end of the post, and if you have decided to give this service a try you may wonder how can you migrate your existing cluster over to AWS.
The process can be a bit complicated, lucky for you there is this awesome post by Sandeep Mehta that guides you step by step.
